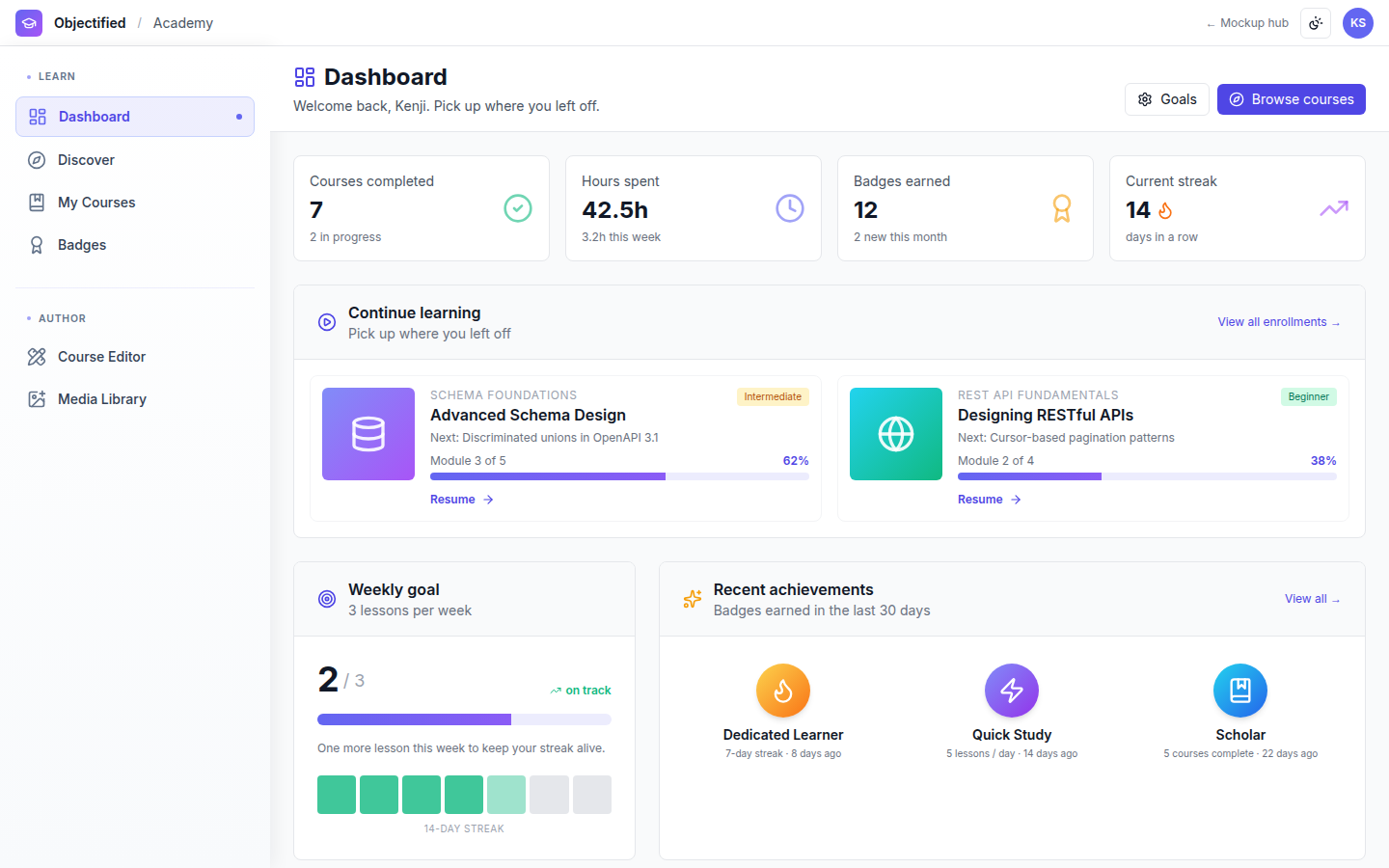
Objectified Data Transform
Schema migrations done right — compatibility, rules, plans, and Spark at scale.
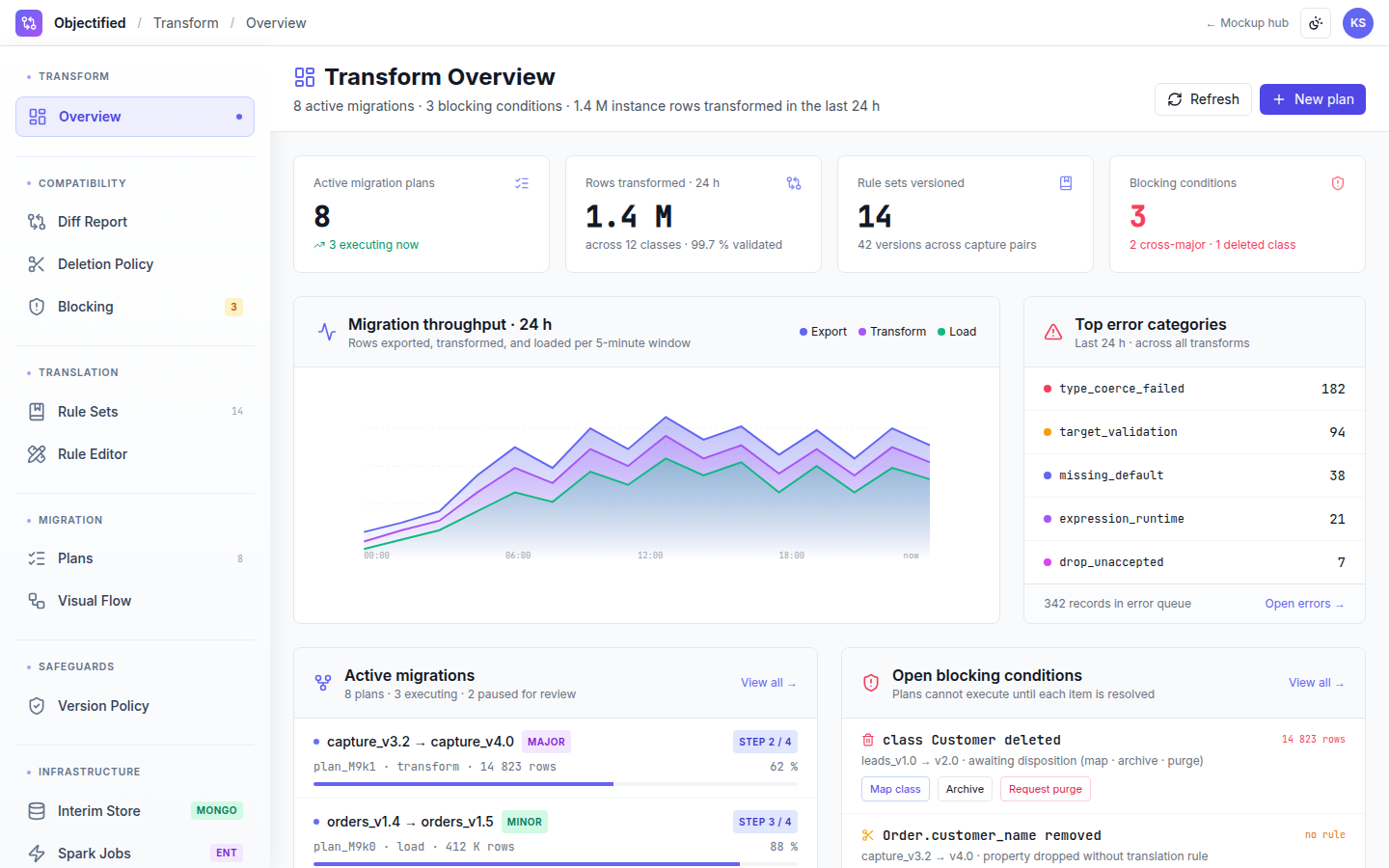
Data Transform handles the gnarly side of evolving schemas at scale: compatibility analysis, declarative translation rules, blocking-condition guardrails, visual migration plans, an interim MongoDB store, and Apache Spark for parallel migrations.
What ships with Data Transform
Every Data Transform surface is wired into the rest of the Objectified platform — no glue code, no separate identity, no bolt-on integrations.
Compatibility report
Diff and classify every change as safe, additive, breaking, or quarantined.
Translation rules
Declarative field-level rules with reusable functions and unit tests.
Blocking conditions
Guardrails that pause migrations on data quality or business-rule violations.
Migration plans
Visual, step-by-step plans with dependencies, rollback, and dry-run mode.
MongoDB interim store
Stage in-flight data before promoting it to your authoritative store.
Spark execution
Parallel migration on Apache Spark for billion-row datasets.
A look inside Objectified Data Transform
Live design previews from the Data Transform mockup pack — 11 surfaces in total.

Declarative translation-rule editor with live before/after preview.

Step-by-step migration plan with dependencies and rollbacks.

Apache Spark jobs panel for parallel mass-migration runs.

The full Data Transform surface map — all 11 screens linked from a single hub.
Use cases
Data Transform is designed around the way real teams actually work — not the way a tool wants them to work.
Roll out a v2 schema across 200 tenants without downtime.
Re-shape historical data into a new model with full lineage retained.
Apply a deletion or redaction policy across an entire portfolio in a single plan.
- Bring-your-own Spark cluster and MongoDB instance
- Policy gates on every plan (4-eyes, security, data-residency)
- Tamper-evident audit log per migration step
- Custom partitioning and parallelism budgets per tenant
- Disaster-recovery snapshots before any major version cut-over
- AI-generated translation rules from sample data
- Plain-English explanations of compatibility findings
- Anomaly detection on row-level transformation outcomes
- Suggested rollback playbooks for each plan
Migrations that explain themselves
AI explains every diff in plain language, generates rules from sample input/output, and picks safe migration sequences with confidence scoring.
Every Data Transform AI feature is grounded in your tenant's data, runs under your data-residency policy, and respects every role and ACL the platform enforces.
Every surface in Objectified Data Transform
A look at the 11 screens designed for this suite — covering everything from day-1 onboarding to day-100 operations.